

Demystifying Training Parameters in LLM - Quality Impact and Sizing Considerations
Training parameters are a pivotal component in the design and performance of LLMs. Choosing optimal size of training parameters depends on data availability, use case, compute resource.

Introduction
Training parameters play a pivotal role in Large Language Models (LLMs) like OpenAI's GPT-3, GPT-4 or Google’s PaLM2. These parameters, serving as the internal knobs and dials, get adjusted during the learning process, refining the model's ability to comprehend and generate text. But how does their adjustment impact the quality of the models? And how many parameters are optimal? Let's simplify these concepts with real-world model examples.
What are Training Parameters?
Training parameters in LLMs refer to the variables that the model learns from the data during the training phase. These include weights and biases, which the model adjusts through backpropagation – a process that minimizes the difference between the model's prediction and the actual output.
Weights: It is a key trainable parameter in a neural network to adjust the influence of each input on the final output.
For instance, if we're trying to predict house prices based on size and location, these two factors become the inputs to our model. However, they may not equally influence the price. The size of the house, often, has a more significant impact on the price than its location. This influence is determined by the "weights" in our model. If size has a larger weight, it means it has a greater contribution to the final price prediction. These weights are learned and refined during the model's training phase.
Biases: It is another key trainable parameter that act like an adjustable constant, providing flexibility to the model's predictions. Think of bias as a kind of baseline or starting point for predictions.
For instance, houses in a specific city might generally start at a certain price, regardless of size or location. This baseline price can be thought of as the bias in our model. Even when the size or location isn't known, the model can still make an accurate prediction thanks to this bias. So, biases help the model make more flexible and precise predictions under various conditions.
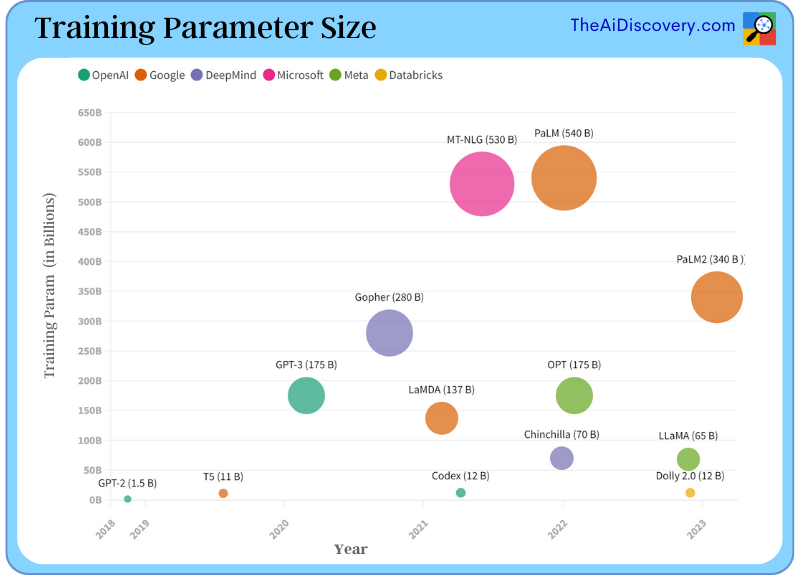
In the below chart, we will visually analyse the parameter count in various models, thereby offering a comparative study of their evolution over time.
How Do Training Parameters Impact Model Quality?
The quality of a language model is directly influenced by the tuning and optimization of its training parameters. Here's how:
Prediction Accuracy: Optimal training parameters lead to higher prediction accuracy. They help the model generalize from the training data to unseen data, thereby improving its performance on various NLP tasks, like text generation, translation, and summarization.
Overfitting and Underfitting: The right balance of parameters can help prevent underfitting (where the model is too simple to capture useful patterns) and overfitting (where the model memorizes the training data, leading to poor performance on new data).
Interpretability: Although LLMs are often seen as "black boxes", understanding their training parameters can provide some insight into their decision-making process. For instance, looking at the weights of different connections can help understand which features the model deems most important.
Bias and Fairness: Training parameters can inadvertently lead to biased predictions if the training data contains biased patterns. Careful monitoring and adjustment of these parameters can help mitigate such biases, leading to more fair and responsible AI.
What Should be the Size of the Training Parameters?
Determining the appropriate size of the training parameters—i.e., the model's complexity—is a critical decision in designing LLMs. Here are a few key considerations:
Data Availability: As a rule of thumb, the more high-quality data available for training, the more complex the model (i.e., the more training parameters) can be.
For instance, Chinchilla model from DeepMind, with its 70 billion parameters trained on a staggering 1.4 trillion tokens, outperformed GPT-3, which had 175 billion parameters but was only trained on 300 billion tokens.
Computational Resources: Training larger models requires more computational resources, both in terms of processing power and memory. This must be balanced against the potential benefits of a more complex model.
Performance Requirements: The complexity of the model should match the complexity of the task. For instance, simple tasks may not benefit from very complex models, while complex tasks may require larger models.
Trade-off Between Precision and Speed: Larger models may provide better performance but at the cost of slower prediction speeds. Depending on the application, this trade-off may or may not be acceptable.
Conclusion
Training parameters are a pivotal component in the design and performance of LLMs. They impact the model's quality in numerous ways, from prediction accuracy to interpretability. Therefore, a thorough understanding and careful optimization of these parameters are crucial for harnessing the full potential of LLMs. The size of these parameters, dictated by factors such as data availability and performance requirements, requires careful consideration, striking the right balance between model complexity, computational efficiency, and application demands.