

How Generative AI Models are Trained
The three key stages of training Generative AI models like GPT: Generative Pre-training, Supervised fine-tuning and Reinforcement Learning with Human Feedback (RLHF)

In the world of artificial intelligence, generative models have garnered significant attention for their ability to create text, images, music, and more. Among these, language models like GPT stand out due to their impressive capability to generate human-like text. But how exactly are these generative AI models trained? This blog will delve into the intricate process behind training a generative AI model, using GPT as a prime example.
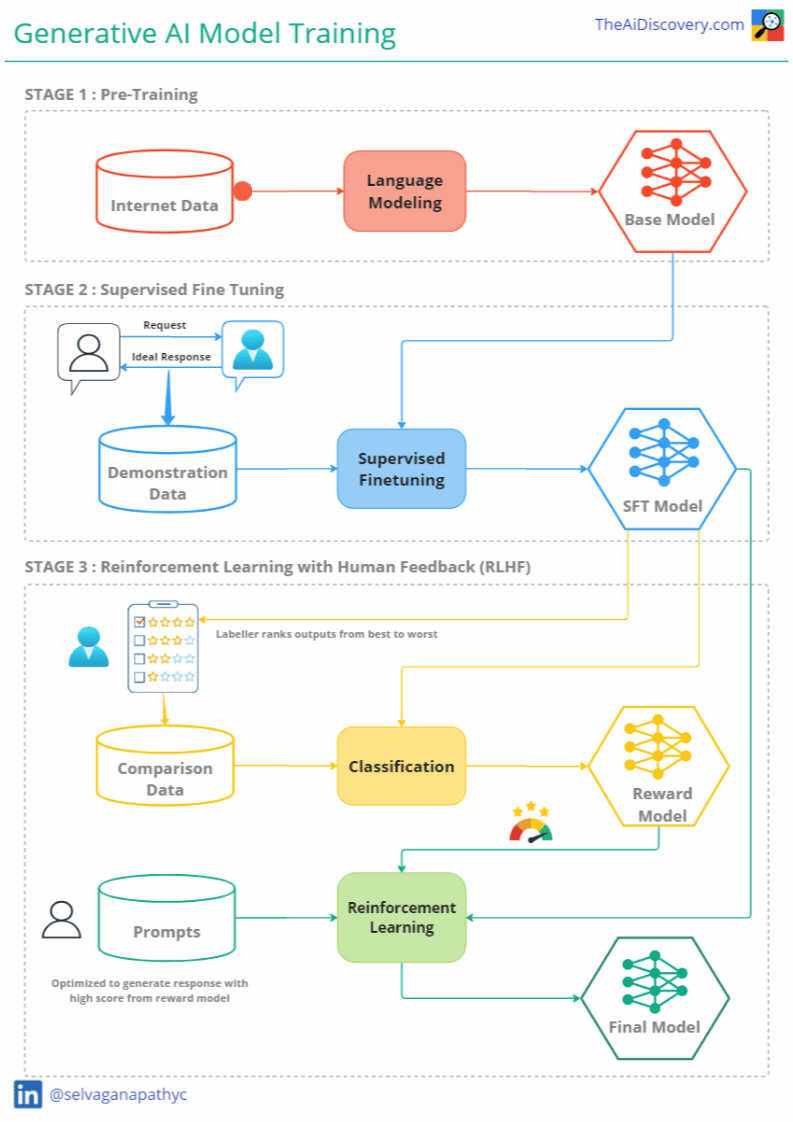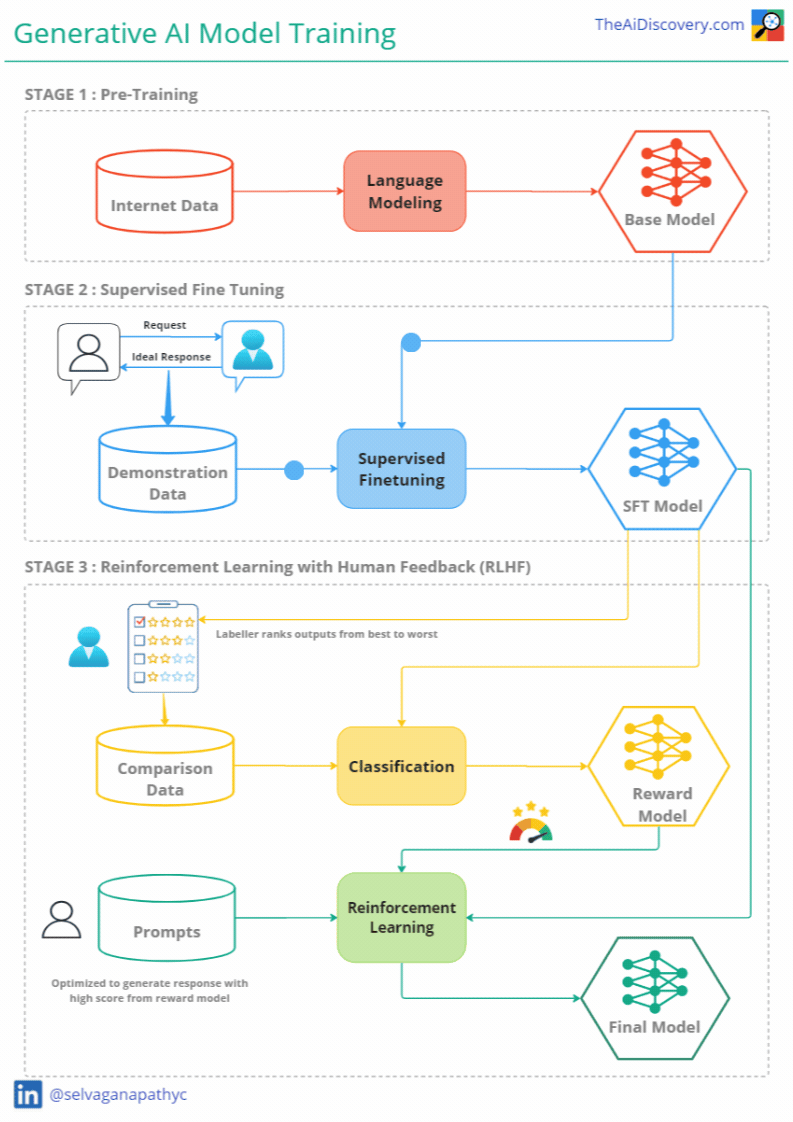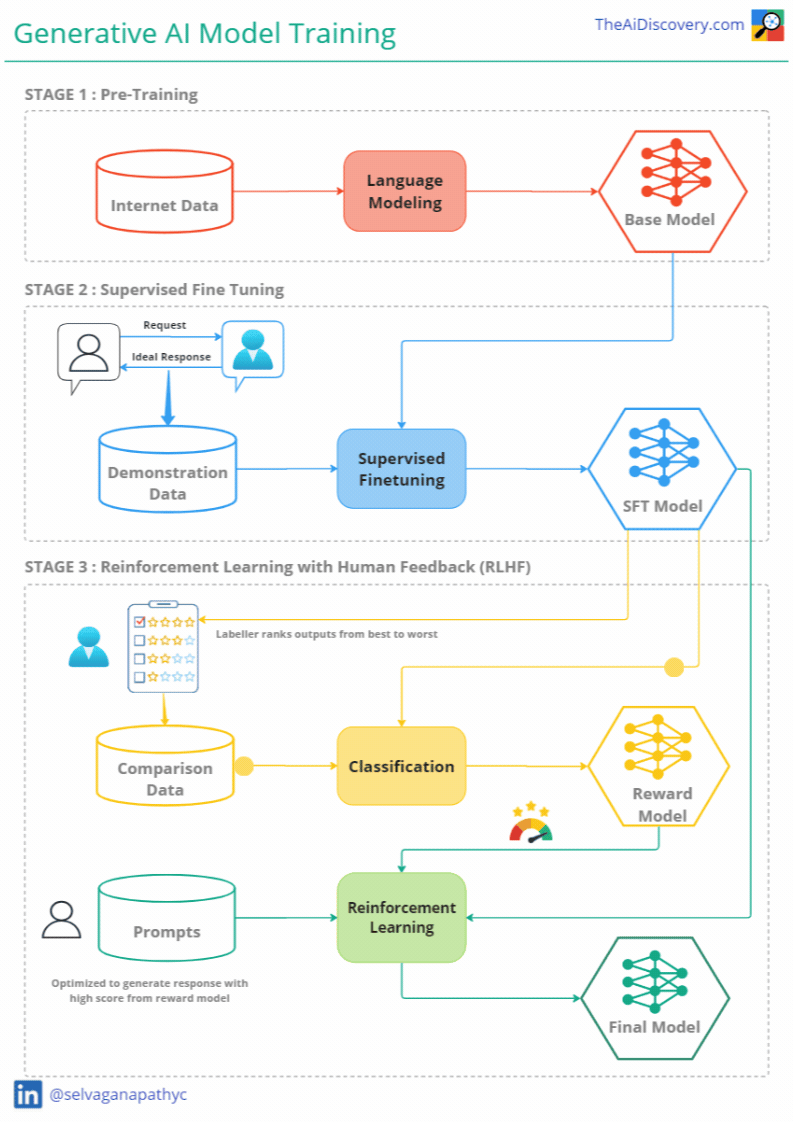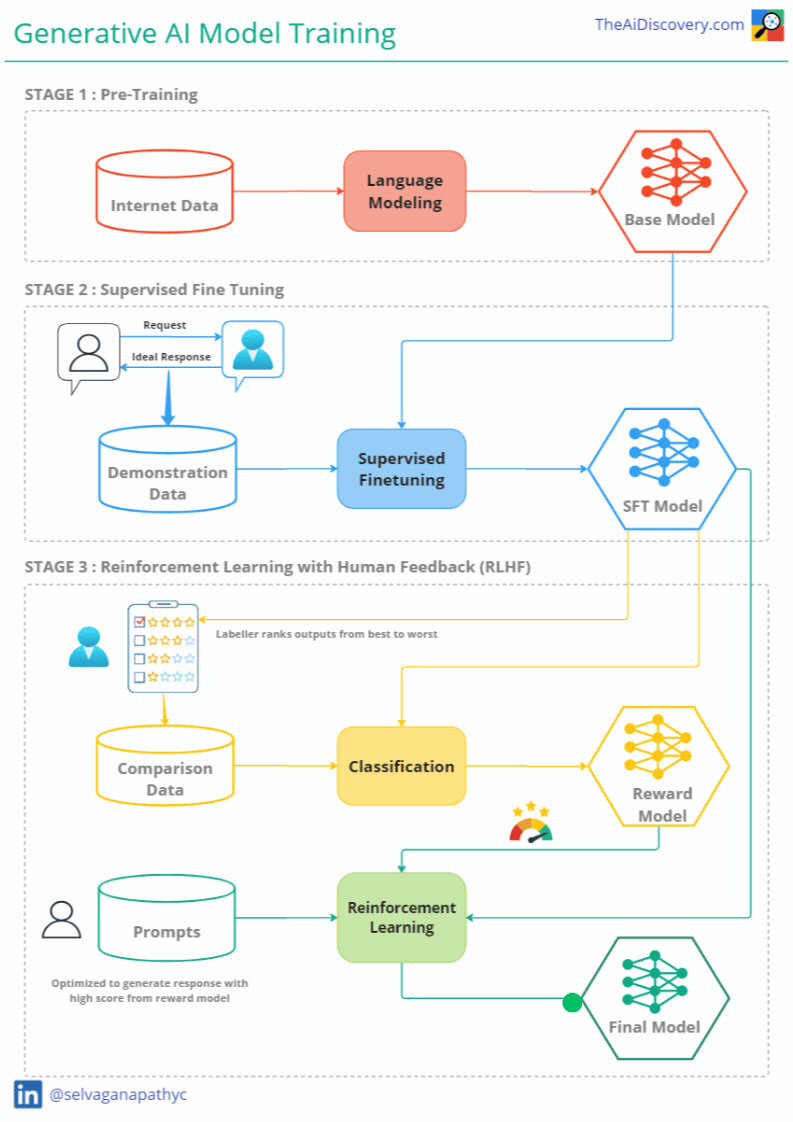
Stages of Training Generative AI Models
Training a generative AI model involves multiple stages, each designed to refine the model’s capabilities and ensure it meets user expectations. Let's break down these stages:
Stage 1 — Generative Pre-Training
Goal: Language understanding & Knowledge Creation
Process: The first stage in training a generative model is pre-training. During this phase, the model is exposed to a vast array of text data sourced from the internet, including websites, books, and articles. This diverse dataset helps the model learn various language patterns, contexts, and styles. The primary objective here is for the model to understand language structure and develop the ability to generate coherent and contextually relevant text.
Resource Requirement:
The dataset used in this phase can be vast, often comprising hundreds of gigabytes to terabytes of text data.
Heavy computation required ~6000 GPUs
12 days
High quantity of data ~10 TB of data
Model Behavior: At this stage, the model can perform text summary, sentiment analysis but lacks the ability to be useful for human interaction.
Stage 2 — Supervised Fine-Tuning (SFT)
Goal: Helpful Assistant
Process: Supervised fine-tuning is the second crucial phase in training generative AI models. Here, the model is fine-tuned on task-specific data to better meet user expectations. For a conversational model like ChatGPT, this involves training the model on curated datasets of human conversations.
Creating Conversations: Human agents simulate conversations, providing ideal responses to various prompts. These crafted dialogues form the training corpus.
Aligning Responses: The conversation histories are aligned with the ideal responses, creating a set of training tokens.
Optimization: The model parameters are updated using algorithms like Stochastic Gradient Descent (SGD), which iteratively improve the model by minimizing errors.
Resource Requirement
Fine-tuning typically requires fewer resources compared to pre-training but still involves significant computational power
1 day
High quality of data ~100K (Request, Response) data
Model Behavior: After fine-tuning, the model becomes more adept at specific tasks, such as generating appropriate and socially acceptable responses in a conversational context.
Stage 3 — Reinforcement Learning through Human Feedback (RLHF)
Goal: Alignment
Process: To further enhance the model's performance, the third stage involves reinforcement learning through human feedback (RLHF). This process allows the model to learn from interactions with real users, refining its responses based on human preferences.
Interactive Learning: The model interacts with users, generating responses to various prompts.
Human Ranking: Human evaluators rank the responses, providing feedback on which ones are most preferred.
Reward Function: A reward model assigns scores to responses based on human feedback, guiding the training process.
Resource Requirement:
RLHF requires ongoing computational resources for continuous interaction and evaluation, often extending over weeks to months.
Human Feedback in the form of comparison labels ~100K to 1M (Comparison labels) and 10K to 100K Prompts
Model Behavior: In this final stage, the model learns to align its responses closely with human preferences, becoming more accurate and user-friendly.
One notable issue is over-optimization, where the model might exploit the reward system, leading to unintended behavior. To mitigate this, techniques such as Kullback-Leibler (KL) divergence are used to maintain a balance between the model’s learned behavior and its fine-tuned responses.
Conclusion
Training generative AI models is a complex, multi-stage process that transforms a basic language model into a sophisticated conversational agent. Starting with generative pre-training to learn language patterns, followed by supervised fine-tuning for task-specific performance, and finally, reinforcement learning through human feedback to refine responses, each stage plays a crucial role in developing a model like GPT.