

Optimizing AI Performance and Cost by Combining RAG and Long Context
Discover how the hybrid approach of combining RAG with long-context LLMs can optimize both performance and cost

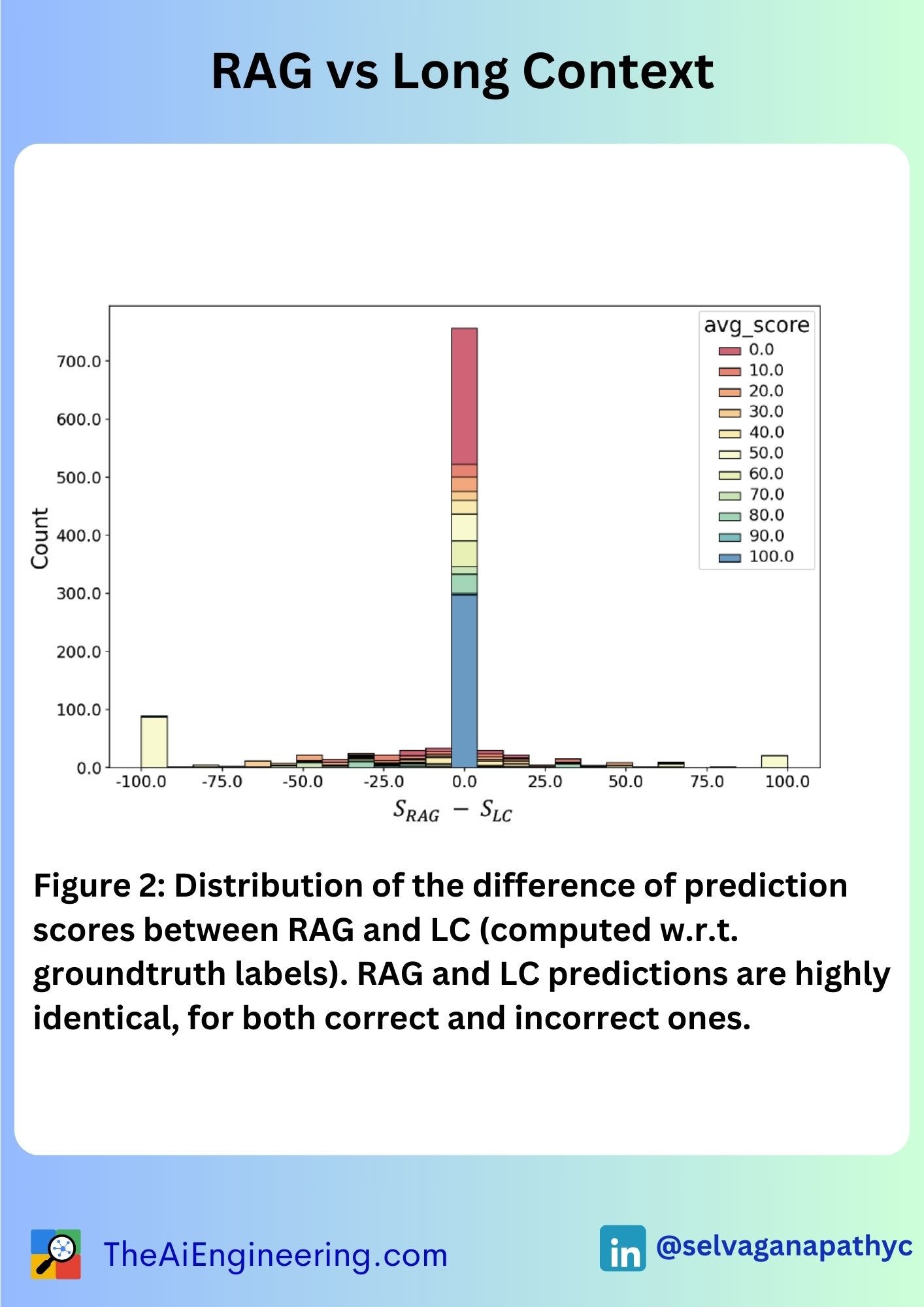
The paper (https://www.arxiv.org/abs/2407.16833) from Google Deepmind and University of Michigan compares Retrieval Augmented Generation (RAG) and long-context (LC) LLMs, finding that LC models generally outperform RAG in terms of performance.
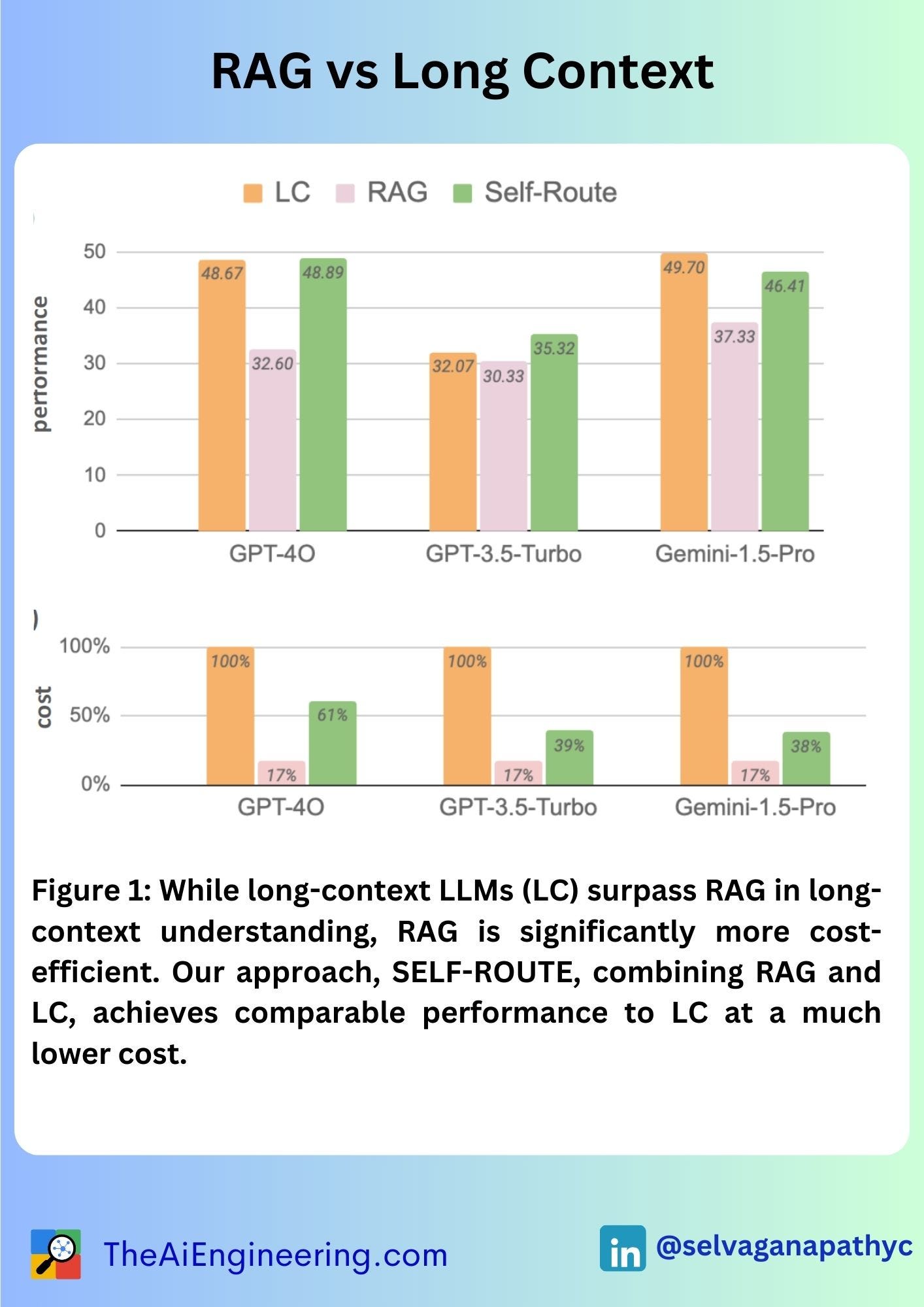

𝗖𝗼𝘀𝘁 𝗘𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝗰𝘆: RAG is significantly more cost-efficient than LC LLMs, making it a viable option when computational resources are limited.
𝗦𝗘𝗟𝗙-𝗥𝗢𝗨𝗧𝗘 𝗠𝗲𝘁𝗵𝗼𝗱: The authors propose SELF-ROUTE, a method that dynamically routes queries to either RAG or LC based on model self-reflection, achieving comparable performance to LC while reducing costs significantly.
𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝗶𝗻𝗴 𝗥𝗲𝘀𝘂𝗹𝘁𝘀: LC LLMs like Gemini-1.5 and GPT-4 consistently outperform RAG across various datasets, with more recent models showing a larger performance gap.
𝗙𝗮𝗶𝗹𝘂𝗿𝗲 𝗔𝗻𝗮𝗹𝘆𝘀𝗶𝘀: Common failure reasons for RAG include multi-step reasoning, general queries, long and complex queries, and implicit queries, providing a direction for future improvements.
𝗣𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝗜𝗺𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻𝘀: The hybrid approach of SELF-ROUTE optimizes both cost and performance, making an advanced AI applications more accessible and efficient.
#AI #AIEngineering