

What is Observability ? Why it's crucial for your SaaS Systems
Observability is a must-have system attribute and crucial aspect of SaaS systems.


Observability
Observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. These external outputs are called telemetry data and include metrics, logs, traces, events. When a user is reporting an issue be it performance issue, error or feature not working the way it is supposed to, they are only reporting the symptoms. Then Software Engineers perform the Root Cause Analysis by identifying all factors that contribute to the problem, connecting events in a meaningful way so that the issue can be addressed. Only by getting to the root of the problem, rather than focusing on the symptoms, is it possible to identify how, when and why the problem occurred.

However, the challenge here is that how do you understand the current system state of your application without shipping new custom code ? Not always you can recreate the issue in QA environment. That is why its important to Instrument your application to emit telemetry data. This will helps you to understand the inner workings and system state solely by observing and interrogating with external tools and thereby making your system to have Observability quality attribute.
Observability Spectrum
A variety of tools and techniques for observing a system are depicted in the figure below. Two ends of the Spectrum are based on the nature of system failures.
Known Unknowns : These are known failure state of the system. For example we know High CPU crossing a threshold say 80% is bad. Monitoring tools are best suited to handle these scenarios. Another tenet of this known failure condition is that a human doesn’t need to sit around watching graphs all day. It can be automated by making system alert the user when something is wrong.
Unknown Unknowns : These are previously unknown failure modes - Your application may have entered into a system state that you haven't seen before and couldn't have expected. The quantity of data and information that is available grows as you move further to the right on the spectrum, but you also require more inquisitive thinking to solve problems. Indeed, machines aren't very adept at figuring out unknown unknowns. Human intervention is needed to analyse the context provided through distributed tracing, logs, and events.
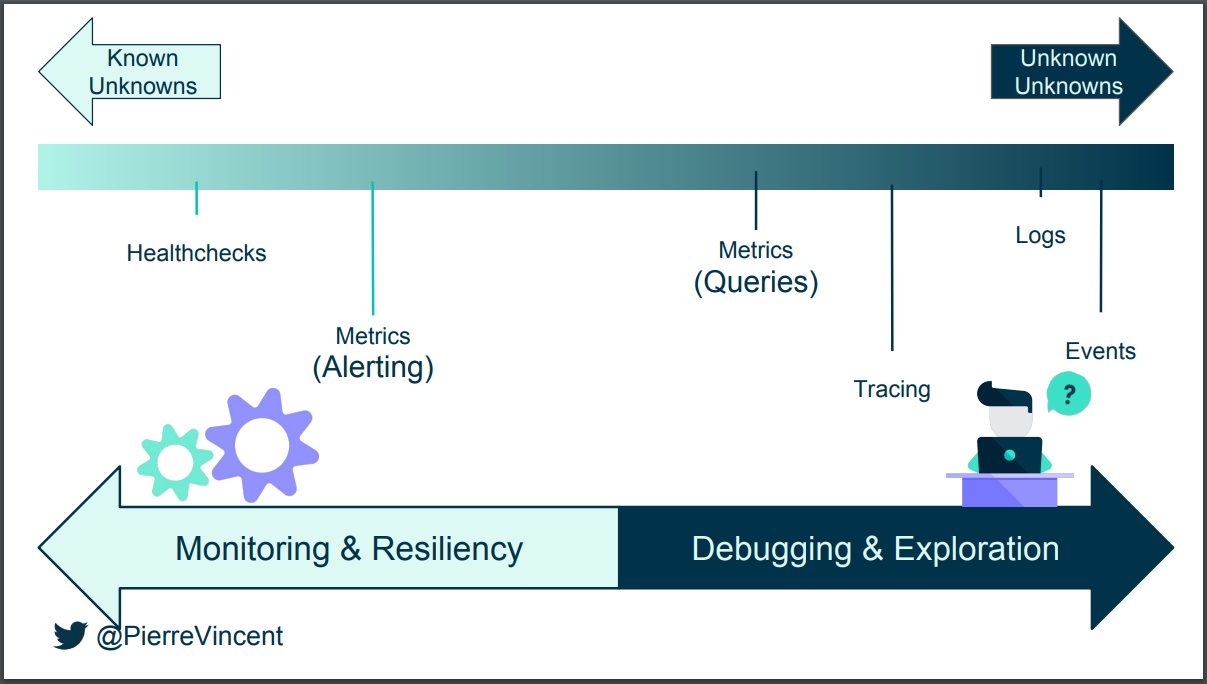
Health Checks are very basic signals that are used to monitor a service's uptime and overall health. Health checks allow the user to pinpoint the malfunction, Latency measurements on specific health checks can be used to predict outages. Usually, automated procedures repurpose these checks to, for instance, cause a service that crashed to restart.
Alerting is an important aspect of observability, allowing companies to be notified of issues in real-time. This can be achieved through a variety of mechanisms, such as email notifications, SMS messages, or push notifications.
Metrics are a numerical representation of data that has been collected over a period of time. Metrics can be used to uncover historical trends, analyse system behaviour at various time intervals, find anomalies in the system, and more. Data can be optimised for storage, processing, retrieval, and querying because most data is kept as counts and numbers. As numerical values require far less storage space, data may be saved for a longer time and utilised to track historical patterns and create various dashboards to gauge the overall health of the system. Two categories of Metrics are:
Platform Metrics - CPU Utilisation, Memory Utilisation, I/O operations.
Application Metrics - Request throughput, error rate, response time
Logs are immutable record of discrete events that happened over time. A log usually includes the timestamp and context payload for an event and can be emitted in three formats - Unstructured Plain text, Structured format like JSON and Binary logs. It is simple to describe any data in the form of a log line because a log is essentially a string, blob of JSON, or typed key-value pairs. Logging is supported by the majority of programming languages, application frameworks, and libraries. Also, adding a log line is as simple as adding a print statement, making logs simple to instrument.
Tracing is a method for monitoring how requests move through a system, correlating events from a user browsing a app all the way through database queries. A trace depicts how a request or action travels across each node of a distributed system from beginning to end. Systems, particularly containerized apps, serverless architectures, or microservices architecture, can be profiled and observed using traces. Tracing is an excellent tool to surface bottlenecks, circular service dependencies, identify areas for performance optimization and enhancements.
Event is a record of all activities that took place during a certain request's interaction with your service. Any interesting information about what happened during that request is associated to that event record, including any unique IDs, variable values, headers, every parameter passed by the request, the execution time, any calls made to remote services, the execution time of those calls, and any other context that might be useful in debugging later.
Observability vs Monitoring
Sometimes, the words "Observability" and "Monitoring" are used synonymously. Following are the key differences between Observability and Monitoring :
Definition : In a strict sense, Observability (a noun) is a System Quality Attribute just like Scalability, Availability, Reliability. It refers to a property of the system on how well we fully comprehend the health and behaviour of the system. However, Monitoring (a verb) is an action you take to help achieve Observability.
Relation: Observability doesn't eliminate the need for monitoring. Monitoring just becomes one of the techniques used to achieve observability. Observability is a superset of monitoring
Goals : The goal of Monitoring is to tell you what is wrong and when it went wrong, while the goal of Observability is to help you understand why and how something went wrong. Monitoring helps to identify issues, but it can’t be used to diagnose problems. Observability, on the other hand, allows you to detect and diagnose issues in real-time.
Capability : Observability provides information about unpredictable failure modes that couldn’t be monitored for. "Observability" seeks to offer rich context and incredibly detailed insights into system behaviour, making it ideal for debugging. Monitoring, on the other hand, is best suited to understand your system’s state using a predefined set of metrics and lets you detect a known set of failure modes.
Need for Observability in SaaS Systems
SaaS is a Complex Distributed System with microservices, containerized components, programmable cloud infrastructure. Almost all SaaS companies are aligning to Cloud native development and Toolset to meet agility and scalability goals. And because of this dynamic and complex landscape, narrowing down the underlying cause of application performance issues can be like searching for a needle in a haystack. Cutting through noise to identify what’s going on is a significant challenge
Increased Availability: Availability is the ability of a system to deliver required services that are requested to do so. Availability ensures that an application or service is continuously available to its users. Availability means the probability that a system is operational at a given time, i.e. the amount of time a System is actually operating as the percentage of total time it should be operating.
Availability = Uptime/ Uptime + Downtime
Observability helps to reduce Mean Time to Detection(MTTD) as Engineers can detect failure modes and the causes of failure in a system quickly. This in turn helps to resolve issues faster and hence reduce Mean Time to Resolution(MTTR)
By quickly resolving issues, organizations can ensure that their systems are always available to users, reducing downtime and improving the uptime.
Improved Reliability: Reliability is the ability of a system to consistently perform according to specifications. It is the degree of consistency of a measure. A system is said to be reliable when it delivers the same repeated results under the same conditions at any point of time, without failures. In multi-tenant SaaS environment, the result or user experience should not change with increasing Tenants or Users. Also if a single tenant uses a disproportionate amount of the resources available in the system, the overall performance of the system should not suffer(noisy neighbour problem).
Observability helps to track critical metrics such as response times, latency, error rates. By monitoring these metrics, you can identify issues and optimize performance and ensure user experience is consistent. Observability also helps to reduce number of outages by proactively detecting issues.
Improved User Experience: Improved reliability, increased uptime, reduced Incident response time result in a better user experience for users of SaaS applications. Observability helps to understand how users interact with your system, identifying issues that affect the user experience. Observability provides organizations with insights into how users are interacting with the SaaS applications. This insights can be used to improve the application design and functionality, resulting in a better user experience.
Enhanced Security : Observing the internal workings of a SaaS system can provide valuable insights into the security of the system and help identify potential vulnerabilities. Many SaaS applications are using sensitive data and need to comply with regulations like GDPR, HIPAA, SOC2, etc. Observability can help you to meet these compliance and regulatory requirements by providing the necessary visibility into your system.
Optimized Cloud Cost: SaaS applications operate on cloud infrastructure and cost of running the application is an important factor. You can’t optimize what you can’t see. Observability helps to identify inefficiencies in your cloud infrastructure. By monitoring the usage of cloud resources, such as CPU, memory, and disk space, observability can help companies identify areas where resources are being underutilized or over provisioned. This information can be used to right-size resources or to consolidate workloads, which can result in significant cost savings and help SaaS companies run their cloud infrastructure more efficiently. This will have direct impact on SaaS companies preserving their bottom line.
Conclusion
In short, Observability is a must-have system attribute and crucial aspect of SaaS systems. It allows you to understand what is happening inside your SaaS system, identify and troubleshoot issues, optimize performance, identify and prevent security threats, monitor the reliability metrics of the services, optimize resource utilization and help meet compliance requirements. This can help to improve the Reliability and Availability of the SaaS application, and can ultimately lead to a better user experience. Therefore, it is crucial to build observability into your SaaS application.
Reference